
 1. ONTOLOGY for the WEB.
1. ONTOLOGY for the WEB.
The Semantic Web = a Web with a meaning.
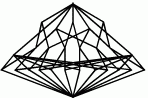
Lattice of top-level categories
The term ONTOLOGY is borrowed from philosophy, where an Ontology is a systematic account of Existence.
In philosophy, an ontology is a theory about the nature of existence, of what types of things exist; ontology as a discipline studies such theories.
Ontology : The science or study of being; that department of metaphysics which relates to the being or essence of things,
or to being in the abstract.
For AI (Artificial-Intelligence) systems, what "exists" is that which can be represented.
Artificial-Intelligence (AI) and Web researchers have co-opted the term for their own jargon, and for them an
ontology is a document or file that formally defines the relations among terms.
The most typical kind of ontology for the Web has a Taxonomy and a set of
Inference Rules.
Taxonomy
: Classification, especially in relation to its general laws or principles;
that department of science, or of a particular science or subject, which consists in or relates to classification; especially the systemic classification of living organisms.
The taxonomy defines classes of objects and relations among them.
Ontologies are often equated with taxonomic hierarchies of classes, class definitions,
and the subsumption relation, but ontologies need not be limited to these forms. Ontologies are also not limited to conservative definitions, that is,
definitions in the traditional logic sense that only introduce terminology and do not add any knowledge about the world
(Enderton, 1972)
To specify a conceptualization one needs to state axioms that do constrain the possible interpretations for the defined terms.
Ontologies are a specification mechanism. An ontology is an explicit specification of a conceptualization.
Inference rules
in ontologies supply further power.
Ontology in the computer science area, specifically in the AI community, it is considered an engineering artifact, constituted by a
specific vocabulary used to describe a certain reality, plus a set of explicit assumptions regarding the intended meaning of the vocabulary
words.
The assumptions has usually the form of a
first order logical
theory where vocabulary words appear as unary (concepts) or binary (relations) predicate names.
In its simplest form an ontology will describe a hierarchy of concepts, as it gets mores sophisticated suitable axioms are added.
Pragmatically, a common ontology defines the vocabulary with which queries and assertions are exchanged among software agents.
Ontological commitments are agreements to use the shared vocabulary in a coherent and consistent manner.
Many definitions of ontologies have surfaced in the last decade.
The term ontology has many meanings and shades of meaning.
It is possible to find in the literature several definitions of ontologies :
"
An ONTOLOGY defines a common vocabulary for researchers who need to share information in a domain.
It includes machine-interpretable definitions of basic concepts in the domain and relations among them."
"
An ONTOLOGY is a model of reality of the world and the concepts in the ontology must reflect this reality."
Ontology Development 101: A Guide to Creating Your First Ontology
Natalya F. Noy and Deborah L. McGuinness
Stanford University, Stanford, CA, 94305
"
The subject of ONTOLOGY is the study of the categories of things that exist or may exist in some domain.
The product of such a study, called an ontology, is a catalog of the types of things that are assumed to exist in a
domain of
interest D from the perspective of a person who uses a language L for the purpose of talking about D.
The types in the ontology represent the predicates, word senses, or concept and relation types of the language L
when used to discuss topics in the domain D."
Building, Sharing, and Merging Ontologies.
John F. Sowa
"
ONTOLOGY : A partial specification of a conceptual vocabulary to be used for formulating knowledge-level theories
about a domain of discourse.
The fundamental role of an ontology is to support knowledge sharing and reuse."
Glossary of Knowledge Modelling Terms.
"ONTOLOGY: A formal, explicit specification of how to represent the objects, concepts,
and other entities in a particular system, as well as the relationships between them."
"
Ontologies are specifications of the concepts in a given field and the relationships among those concepts."
"
ONTOLOGY : explicit specification of a shared conceptualization that holds in a particular context"
A sum up from
Guus Schreiber
SWI, University of Amsterdam.
In the opinion of
• Dieter Fensel
and Frank van Harmelen,
Vrije Universiteit , Amsterdam
• Ian Horrocks,
University of Oxford, Computing Laboratory, UK
• Deborah L. McGuinness,
Stanford University
• Peter F. Patel-Schneider
, Bell Laboratories
autors of: OIL
- An Ontology Infrastructure for the Semantic Web,
the best characterizes an ontologys essence is this:
"
An ONTOLOGY is a formal, explicit specification of a shared conceptualization."
In this context, conceptualization refers to an abstract model of some phenomenon in the world that identifies that phenomenons relevant concepts.
Explicit means that the type of concepts used and the constraints on their use are explicitly defined,
(the precision of concepts and their relationships is clearly defined) and
a precise mathematical description hints the word formal, means that the ontology should be machine understandable.
Different degrees of formality are possible.
Shared reflects the notion that an ontology captures consensual knowledge - that is, it is not restricted to some individual but is accepted by a group.
Ontologies can be used to support a great variety of tasks in diverse research areas such
as knowledge representation, natural language processing, information retrieval, databases, knowledge management, on line database integration, digital libraries,
geographic information systems, visual information retrieval or multi agent systems.
Ontologies can enhance the functioning of the Web in many ways.
They can be used in a simple fashion to improve the accuracy of Web searches - the
search program can look for only those pages that refer to a precise concept instead of all the ones using ambiguous keywords.
More advanced applications will use ontologies to relate the information on a page to the associated knowledge structures and inference rules.
"
Knowledge Base: An informal term for a collection of information that includes an ONTOLOGY as one component.
Besides an ontology, a knowledge base may contain information specified in a declarative language such as logic
or expert-system rules, but it may also include unstructured or unformalized information expressed
in natural language or procedural code.
"
By itself, logic says nothing about anything, but
the combination of logic with an ontology provides a language that can express relationships about the entities in the domain of interest.
"
Knowledge Interchange Format
- KIF - : a PARTICULAR LOGIC LANGUAGE, has been proposed as a standard to use to describe things within
computer systems, e.g. expert systems, databases, intelligent agents, etc.
KIF is a prefix version of
First order predicate logic
with Set Theory
(here - down)
with Logically comprehensive extensions to support non-monotonic reasoning, definitions and
Model-theoretic semantics.
The language description includes both a specification for its syntax and one for its semantics."
" For the processing of the knowledge available in the Semantic Web are inference engine necessary. "
Inference engines deduce new knowledge from already specified knowledge.
Two different approaches are applicable here:
(1)logic based inference engines and (2) specialized algorithms (Problem Solving Methods).
Context–References–Weblinks:
–
What is an Ontology?
– Autor: Tom Gruber –
<Thomas R. Gruber> – Knowledge Systems Laboratory, Stanford University.
–
Toward Principles for the Design of Ontologies - Used for Knowledge Sharing.
(PDF) 1993 – <Thomas R. Gruber>
– KSL Stanford University.
–
Knowledge Interchange Format
From Wikipedia, the free encyclopedia.
–
Knowledge Interchange Format (KIF).
(PDF)
–
First-Order Predicate Calculus.
(PDF)
–
First-Order Logic.
(also known as first-order predicate calculus) - from Wolfram MathWorld.
–
First-Order Logic.
From Wikipedia, the free encyclopedia.
–
Predicate logic.
From Wikipedia, the free encyclopedia.
–
Glossary of First-Order Logic.
Peter Suber,
Department of Philosophy, Earlham College, Richmond, Indiana, 47374, U.S.A.
–
Set Theory.
Stanford Encyclopedia of Philosophy.
–
Set Theory.
What are sets? (PDF)
–
Set Theory.
List of homepages of set theorists, inspired by
Computability Theory
–
A history of set theory.
The history of set theory...
–
4.4.5 Theory of Sets.
Mathematical Markup Language (MathML) Version 3.0 - W3C Recommendation 21 October 2010.
–
Basic Notions of Modeltheoretic Semantics.
–
Model-Theoretic Semantics.
OWL 1.1 Web Ontology Language - W3C Working Draft 8 January 2008.
–
Model-Theoretic Semantics.
OWL 2 Web Ontology Language - W3C Working Draft 11 April 2008.
–
A Model-Theoretic Semantics.
for DAML+OIL (March 2001).
Internet provides the infrastructure to enable global communication and ontologies provide a shared and common understanding of a domain,
their marriage allows the representation of domain knowledge,
that can be communicated between people and heterogeneous and distributed application systems.
3. Ontology Languages.
While HTML allows us to visualize the information on the web, it doesn't provide much capability
to describe the information
in ways that facilitate the use of software programs to find or interpret it.
Querying the Web today can be a frustrating activity because the results delivered by syntactically oriented search engines often do
not match the intentions of the user.
This problem is caused by the Webs lack of semantic structures that could be exploited during the search process.
However, XML has a limited capability to describe the relationships (schemas or ontologies) with respect to objects.
The use of ONTOLOGIES provides a very powerful way to describe objects and their relationships to other objects.
 SHOE: Simple HTML Ontology Extensions.
SHOE: Simple HTML Ontology Extensions.
An important early ontology language was the Simple HTML Ontology Extensions (SHOE) language developed by students at the University of Maryland.
SHOE is a small extension to HTML which allows web page authors to annotate their web documents with machine-readable knowledge.
SHOE makes real intelligent agent software on the web possible.
HTML was never meant for computer consumption; its function is for displaying data for humans to read.
The "knowledge" on a web page is in a human-readable language
, laid out with tables and graphics and frames in ways that we as humans comprehend visually.
Unfortunately, intelligent agents aren't human.
Even with state-of-the-art natural language technology, getting a computer to read and
understand web documents is very difficult.
This makes it very difficult to create an intelligent agent that can wander the web on its own, reading and comprehending web pages as it goes.
SHOE eliminates this problem by making it possible for web pages to include knowledge that intelligent agents can actually read.
SHOE - Simple HTML Ontology Extensions, a KR language which allows web pages to be annotated with semantics.
SHOE allows authors to annotate their pages with ontology-based knowledge about page contents.
SHOE allows users to issue queries that are much more sophisticated than keyword search techniques, including queries that require retrieval of information from many sources.
SHOE: Context–References–Weblinks:
–
SHOE
- Parallel Understanding Systems Group - Department of Computer Science - University of Maryland.
–
Semantic Interoperability on the Web
(PPT) - Autor: Jeff Heflin and James Hendler, University of Maryland.
–
SHOE Publications
- Parallel Understanding Systems Group - Department of Computer Science - University of Maryland.
–
SHOE: A Blueprint for the Semantic Web
(PDF) - Autor: Heflin, J., Hendler, J., and Luke, S. Semantic Web. MIT Press, Cambridge, MA, 2003.
–
Shoes FAQ - A guide to....
–
The SHOE FAQ
- Parallel Understanding Systems Group - Department of Computer Science - University of Maryland.
–
Simple HTML Ontology Extensions (SHOE)
Cover Pages – OASIS, Organization for the Advancement of Structured Information Standards.
–
Simple Ontology Extensions
(PPT) Autor: Ahmet Selman Bozkir - Hacettepe University Computer Eng. Dept.
–
Simple Ontology Extensions
(PPT) Autor: Ahmet Selman Bozkir - Hacettepe University Computer Eng. Dept.
–
Towards the Semantic Web: Knowledge Representation in a Dynamic, Distributed Environment
Dissertation: Jeffrey Douglas Heflin, Doctor of Philosophy,
Ph.D. Thesis, University of Maryland, College Park. 2001. (PDF)
Development of the web ontology languages (History):
from RDF(S) to OWL Web Ontology Language.

OIL: Ontology Interchange Language. (Ontology Inference Layer)
(OIL) (the Ontology Inference Layer)
OIL (Ontology Interchange Language / Ontology Inference Layer) proposes a
" a joint standard for integrating ontologies with exisiting and arising web standards ".
OIL is a Web-based representation and inference layer for ontologies, which combines the widely used modeling
primitives from frame-based languages with the formal semantics and reasoning services provided by Description Logics(DL).
XML can be used as a serial syntax for OIL. The syntax of OIL is oriented towards XML and RDF.
Furthermore, OIL is the first ontology representation language that is properly grounded in W3C standards such as RDF/RDF-schema and XML/XML-schema.
OIL unifies three important aspects: Formal semantics and efficient reasoning support as provided by (1) Description Logics, (2) epistemological rich modeling
primitives as provided by Frame languages, and a (3) standard proposal for syntactical exchange notations as provided by the Web community.
(1)
Description Logics (DL)
describe knowledge in terms of concepts and role restrictions that are used to automatically derive
classification taxonomies. They provide theories and systems for expressing structured knowledge, for accessing it and reason-ing with it in a principled way.
Description Logics allow specifying a terminological hierarchy using a restricted set of first order formulas.
They usually have nice computational properties (often decidable and tractable, or at least seem to have nice average computational properties),
but the inference services are restricted to classification and subsumption.
That means, given formulae describing a classes, the classifier associated with a certain description logic will place them inside a hierarchy, and given an instance description, the classifier will determine the most specific classes to which the particular instance belongs.
From a modeling point of view, Description Logics correspond to monadic/dyadic Predicate Logic statements with three variables.
(2)
Frame-based systems
provide as central modeling primitive classes (i.e., frames) with certain properties called attributes.
These attributes do not have a global scope but are only applicable to the classes they are defined for.
A frame provides a certain context for modeling one aspect of a domain.
(3) Web standards: XML and RDF. Given the current dominance and importance of the WWW, a syntax of an ontology language must be
formulated using existing web standards for information representation. The XML schema syntax
of OIL was mainly defined as an extension of XOL (XML-Based Ontology Exchange Language).
OIL is also defined on top of the
Resource Description Framework RDF and RDF schema.
OIL shares many features with
OKBC
(Open Knowledge Base Connectivity) and defines a clear semantics and XML-oriented syntax for them.
In the same way that OIL provides an extension to OKBC
(and is therefore downward compatible with OKBC) it also provides an extension to RDF and RDFS.
Based on its RDF syntax, ontologies written in OIL are valid RDF documents.
OIL extends the schema definition of RDFS.
Based on these extensions an ontology in OIL can be expressed in RDFS.
Context–References–Weblinks:
–
Ontology Interchange Language (OIL)
Cover Pages – OASIS, Organization for the Advancement of Structured Information Standards.
–
OIL Home Page
Ontoknowledge
–
OIL in a Nutshell
- Autor:
Dieter Fensel;
Ian Horrocks;
Frank van Harmelen;
Stefan Decker;
Dr. Michael Erdmann;
Michel Klein
–
Questions and answers on OIL
- Autor: Frank van Harmelen;
Ian Horrocks
–
RESOURCES: Description Logics
- maintained by
Carsten Lutz - Univärsität Bremen.
–
DL-Learner: Learning Concepts in Description Logics
(PDF) - <Jens Lehmann>
- Department of Computer Science, University of Leipzig.
–
An Introduction to Description Logics
(PDF) - Autor: Daniele Nardi, Ronald J. Brachman.
–
Description Logics: Logics and Ontologies.
(PDF) - <Enrico Franconi> - Department of Computer Science, University of Manchester.
–
The Role of Frame-Based Representation on the Semantic Web.
Autor:Ora Lassila - Nokia Research Center;
Deborah McGuinness -
Knowledge Systems, AI Laboratory Stanford University.
– Schemabasierte P2P-Netzwerke -
Techn. Hilfsmittel:RDF, OIL
(PDF) - Univärsität Leipzig.
DAML: DARPA Agent Mark Up Language (or DAML- ONT)
• DAML-S: Semantic Markup for Web Services.
– DARPA – (AML)
US Defense Advanced Research Projects Agency.

RDF
was developed by the W3C at about the same time as XML, and it turns out to be an excellent complement to XML,
providing a language for modeling semi-structured metadata and enabling
knowledge-management applications.
The RDF
core model is successful because of its simplicity.
The W3C also developed a purposefully lightweight schema language,
RDF Schema
(RDFS), to provide basic structures such as classes and properties.
As the ambitions of RDF and XML have expanded to include things like the Semantic Web,
the limitations of this lightweight schema language have become evident.
Accordingly, a group set out to develop a more expressive schema language, DARPA Agent Markup Language (DAML).
"The goal of the DAML program is to create technologies that will enable software
agents to dynamically identify and understand information sources, and to provide interoperability between agents in a semantic manner."
Although DAML is not a W3C initiative, several familiar faces from the W3C, including Tim Berners-Lee, participated in its development.
DAML designer Jim Hendler :
" has begun working with Berners-Lee and the World Wide Web Consortium to make sure that DAML fits with the W3C's plans for a semantic Web,
which would be based primarily on RDF (Resource Description Framework), the W3C's metadata technology for adding machine-readable data to the Web. "
Professor James A. Hendler
, Department of Computer Science
, Rensselaer Polytechnic Institute
The DAML language is being developed as an extension to
XML
and the Resource Description Framework (RDF).
"The DARPA Agent Mark-Up Language (DAML) (or DAML-ONT) is being designed as an XML-based
semantic language that ties the information on a page to machine-readable semantics (ontology)."
RDF provide a basic feature set for information modeling.
RDF is very similar to a basic
directed graph
, which is a very well understood data structure in computer science.
This simplicity serves RDF very well, making it a sort of assembly language on top of which almost every other information-modeling method can be overlaid.
However, users have desired more from RDF and RDF Schema, including data types, a consistent expression for enumerations, and other facilities.
Logicians, some of whom see RDF as a possible tool for developing long-promised practical AI systems, have bemoaned the rather thin set of facilities provided by RDF.
In response the DARPA Agent Markup Language (DAML) sprang from a U.S. government-sponsored effort in August 2000,
which released DAML-ONT, a simple language for expressing more sophisticated RDF class definitions than permitted by RDFS.
DAML: Context–References–Weblinks:
– The DARPA Agent Markup Language
Homepage.
– About the DAML Language.
– DAML Organisation.
– DAML Briefings
– DAML Organisation.
– Knowledge Sharing Effort
– DARPA – From Wikipedia, the free encyclopedia.
– Directed Graphs (PDF)
– Graphs
– Princeton University
– Directed Graphs
– Russian Academic dictionaries and encyclopedias.
– Directed Graphs
– Autor: Kenneth R. Koehler –
University of Cincinnati, Raymond Walters College.
– DARPA Agent Markup Language (DAML) Status and Tools.
by Dan Connolly
- W3C - World Wide Web Consortium.
– DAML Tools
– DAML Organisation.
– Resource Description Framework (RDF)
- W3C - World Wide Web Consortium.
 • DAML-S: Semantic Markup for Web Services / DAML-Enabled Web Services.
• DAML-S: Semantic Markup for Web Services / DAML-Enabled Web Services.
The DARPA Agent Markup Language (DAML) program aims to allow one to mark up web pages to indicate the meaning of their content.
The Semantic Web should enable greater access not only to content but also to services on the Web.
Users and software agents should be able to discover, invoke, compose, and monitor Web resources
offering particular services and having particular properties.
As part of the DARPA Agent Markup Language program, an ontology of services, called DAML-S, that will
make these functionalities possible.
Among the most important web resources are those that provide services.
By service we mean Web sites that do not merely provide static information but
allow one to effect some action or change in the
world, such as the sale of a product or the control of a physical device.
The Semantic Web should enable users to locate, select, employ, compose, and monitor Web-based services automatically.
To make use of a Web service, a software agent needs a computer-interpretable description of the
service, and the means by which it is accessed. An important goal for DAML, then, is to establish a
framework within which these descriptions are made and shared. Web sites should be able to employ
a set of basic classes and properties for declaring and describing services, and the ontology structuring
mechanisms of DAML provide the appropriate framework within which to do this.
Services can be primitive in the sense that they invoke only a single Web-accessible computer program,
sensor, or device that does not rely upon anotherWeb service, and there is no ongoing interaction between
the user and the service, beyond a simple response. For example, a service that returns a postal code or the
longitude and latitude when given an address would be in this category. Or services can be complex, composed
of multiple primitive services, often requiring an interaction or conversation between the user and
the services, so that the user can make choices and provide information conditionally. Ones interaction
with www.amazon.com to buy a book is like this; the user searches for books by various criteria, perhaps
reads reviews, may or may not decide to buy, and gives credit card and mailing information.
DAML-S is meant to support both categories of services, but of course, complex services have provided the primary
motivations for the features of the language.
The following four sample tasks will give the reader an idea of the kinds of tasks we expect DAML-S to enable.
1. AutomaticWeb service discovery.
2. Automatic Web service invocation.
3. Automatic Web service composition and interoperation.
4. AutomaticWeb service execution monitoring.
The service profile tells what the service does; that is, it gives the type of information needed by a
service-seeking agent to determine whether the service meets its needs.
A service profile provides a high-level description of a service and its provider; it is used to
request or advertise services with discovery/location registries.
Service profiles consist of three types of information:
• a human readable description of the service;
• a specification of the functionalities that are provided by the service; and
• a host of functional attributes which provide additional information and
requirements about the service that assist when reasoning about several services with similar capabilities.
A more detailed perspective on services is that a service can be viewed as a process.
The two chief components of a process model are the process, which describes a service in terms of its
component actions or processes, and enables planning, composition and agent/service interoperation; and
the process control model, which allows agents to monitor the execution of a service request.
DAML-S is an attempt to provide an ontology, within the framework of the DARPA Agent Markup Language, for describing Web services.
It will enable users and software agents to automatically discover,
invoke, compose, and monitor Web resources offering services, under specified constraints.
DAML+OIL: Semantic Markup language for Web Resources.
The DAML group soon pooled efforts with the Ontology Inference Layer (OIL), another
effort providing more sophisticated classification, using constructs from frame-based AI.
Since then, an ad hoc group of researchers has formed the
" Joint US/EU committee on Agent Markup Languages "
"
The result of these efforts is DAML+OIL, a language for expressing
far more sophisticated classifications and properties of resources than RDFS."
The DAML+OIL ontology language is much richer in many ways than the SHOE language was.
DAML+OIL is a semantic markup language for Web resources.
The DARPA Agent Markup Language (DAML) is being developed as an extension to XML and the Resource Description Framework (RDF).
It builds on earlier W3C standards such as RDF and RDF Schema, and extends these languages with richer modelling primitives.
DAML+OIL provides modelling primitives commonly found in frame-based languages.
DAML+OIL (March 2001) extends DAML+OIL (December 2000) with values from
XML Schema datatypes.
The language has a clean and well defined semantics.
A DAML+OIL knowledge base is a collection of
RDF triples.
(
What is an rdf triple?)
(W3C rdf triple)
DAML+OIL prescribes a specific meaning for triples that use the DAML+OIL vocabulary.
The model-theoretic semantics specifies exactly which triples are assigned a specific meaning, and what this meaning is.
DAML+OIL shows how modern ontology languages are becoming more powerful and also more embedded on the web -- that is, they are more tied into advanced web languages.
( One key difference between DAML+OIL and SHOE is that DAML+OIL does not assume that the markup lives on the same page as the object being described.
In fact, the practice has become to have a separate page, using a ".daml" extension, which describes information in a manner intended for computers, not for humans.
The DAML+OIL ontology language is much richer in many ways than the SHOE language was.)
However, as the languages get more complicated, it gets harder for users to harness the full expressivity of the language, and harder
for users to check to see whether the ontology someone else designed has the meaning they expect.
There are a number of research areas that are opened up by these languages,
and their complexity, including issues of tool design, language display, and the use of the ontologies by more complex web agents.
DAML+OIL: ContextReferencesWeblinks:
–
DAML+OIL
– (DAML Organisation - December 2000)
–
An Axiomatic Semantics for RDF, RDF-S, and DAML+OIL
– Richard Fikes, Deborah L McGuinness, Knowledge Systems Laboratory, Stanford University.
–
An Axiomatic Semantics for RDF, RDF-S, and DAML+OIL
– Richard Fikes, Deborah L McGuinness – W3C Note 18 December 2001.
OWL: Web Ontology Language.
• OWL : Web Ontology Language.
• OWL-S : OWL-based Web Service Ontology.
"
The task of classifying all the words of language, or what's the same thing, all the ideas that seek expression, is the most
stupendous of logical tasks.
Anybody but the most accomplished logician must break down in it utterly;
and even for the strongest man, it is the severest possible tax on the logical equipment and faculty."
Charles Sanders Peirce
, letter to editor B. E. Smith of the Century Dictionary. –
(peirce.org)
"
The art of ranking things in genera and species is of no small importance and very much assists our judgment as well as our memory.
You know how much it matters in botany, not to mention animals and other substances, or again moral and notional entities as some call them.
Order largely depends on it, and many good authors write in such a way that their whole account could be divided and subdivided according
to a procedure related to genera and species.
This helps one not merely to retain things, but also to find them.
And those who have laid out all sorts of notions under certain headings or categories have done something very useful."
Gottfried Wilhelm Leibniz
, New Essays on Human Understanding.
The World Wide Web and digital libraries are enormous repositories which concentrate huge volumes of distributed heterogeneous data.
The accessibility, maintenance, organization, preservation among other required tasks to manage these repositories as efficient
as possible overcome human capabilities, in such a way that to carry them out, it is necessary the support of automatic processes or tools.
To achieve with this goal, an appropriated way to describe these repositories and their data machine understandable is required.
Many alternatives have been developed, however, there is not a consensus to use one or a small set of them yet.
Artificial Intelligence is a research area which has proposed important
approaches as data structures, relational data bases, mathematic logic, procedures, taxonomies among others. One of these proposals termed ontologies.
Ontologies emerged as an alternative to represent knowledge.
However, they have been used to support a great variety of tasks.
At present, there are applications of ontologies with commercial, industrial, academical or research focuses.
People, organizations and software programs must communicate, although different needs and backgrounds imply different viewpoints.
This divergence is natural and valuable, but it leads to problems in communication, interaction and understanding.
Ontologies are an alternative to address these kind of problems.
• OWL: Web Ontology Language.
OWL (Ontology Web Language) is being developed by the W3C
Web-Ontology (WebOnt) Working Group (Closed).
Mail from Professor James Hendler: «
So Long and thanks for all the fish »
A new W3C OWL website
has been developed for providing more information about OWL.
OWL has more facilities for expressing meaning and semantics than XML, RDF, and RDF-S, and thus OWL goes beyond these languages in its ability to represent machine interpretable content on the Web.
OWL is a revision of the DAML+OIL web ontology language incorporating lessons learned from the design and application of DAML+OIL.
OWL provides a basic infrastructure that allows a machine to make the same sorts of simple inferences that human beings do.
Re: Which kind of ontology is OWL specification? e-mail message: from Jim Hendler:
Received on Sunday, 4 January 2004 15:27:50 EST
- Previous message: Jim Hendler: "Re: "Transitive over" properties"
- In reply to: wwmm: "Which kind of ontology is OWL specification?"
- Help: [ How to use the archives ] [ Search in the archives ]
This archive was generated by hypermail pre-2.1.9 :
Sunday, 4 January 2004 15:27:51 EST
W3C home > Mailing lists > Public > public-webont-comments@w3.org > January 2004
From: Jim Hendler <References="hendler@cs.umd.edu>
Date: Sun, 4 Jan 2004
At 1:00 PM +0800 1/2/04, wwmm wrote:
>
> Is OWL specification a ontology?
> If so, Which kind of ontology is OWL specification?
> It is a representational ontology or task ontology?
> Yours sincerely
You ask a hard question - because it hinges on exactly what one defines as an ontology, a representational ontology, or a task
ontology.
OWL is precisely specified in our documents and in a sense the only true answer to your question is "what is in the documents is
what OWL is" --- that said, perhaps the following will be useful in helping you to answer your own question:
1 - OWL minimizes the "content" component purposely (by charter) - in other words OWL is not a specific set of content, but rather a
convention for expressing content. There are some terms which are defined by OWL (or used consistently from RDF and RDF Schema), but in
general it is meant to be a language for defining ontologies - not an "ontology" unto itself
2 - OWL has been used in many cases to define what has sometimes
been called a "representational ontology" where that means soemthing like a specification of physical entities and their relationships.
Many good examples of this can be found in the DAML Ontology Library [1]
3 - OWL has also been used to define "task" or "process" ontologies,
where this term is used to mean a description of things in the world that change over time or a description of what the AI community has
called in the past "planning operators." The best example I know of this can be found in the OWL-S work, which aims to use OWL to provide
semantics for Web Service applications [2].
I hope this helps.
Jim Hendler
[1] http://www.daml.org/ontologies/
[2] http://www.daml.org/services/owl-s/1.0/
Professor James Hendler
http://www.cs.umd.edu/users/hendler
Director, Semantic Web and Agent Technologies 301-405-2696
Maryland Information and Network Dynamics Lab. 301-405-6707 (Fax)
Univ of Maryland, College Park, MD 20742 240-277-3388 (Cell)
Professor Hendler has moved from the University of Maryland....
Professor James A. Hendler
, Department of Computer Science
, Rensselaer Polytechnic Institute
- – References, WebLinks:
-
• OWL-S
: OWL-based Web Service Ontology.
OWL Web Ontology Language for Services (OWL-S )
Weblinks:
–
OWL for Services (OWL-S) - Tools.
DAML.org
–
XML declarative description with FIRST-ORDER LOGICAL CONSTRAINTs (FLCs)
(PDF)
Autor:
• CHUTIPORN ANUTARIYA,
Computer Science Program,
Shinawatra University, Pathumthani 12160, Thailand.
• VILAS WUWONGSE,
Computer Science and Information Management Program,
Asian Institute of Technology, Pathumthani 12120, Thailand
• KIYOSHI AKAMA,
Center for Information and Multimedia Studies, Hokkaido University
, Sapporo 060, Japan.
|
ACRONYM |
LANGUAGE |
CHARACTERISTICS |
| HTML |
Hyper Text Markup Language |
Simplicity |
| XML |
Extensible Markup Language |
Extensions for arbitrary domains and specific tasks. |
| XSL |
Extensible Stylesheet Language |
It provides a standard to describe mappings between different terminologies,
(a translation mechanism between XML documents). |
| SHOE |
Simple HTML Ontology Extensions |
It is a XML compatible knowledge representation language for the web.
It allows page authors to annotate their web documents.
It is not actively maintained. |
| RDF |
Resource Description Framework |
Syntactic conventions and simple data models to represent semantics.
It supports interoperability aspects with object - attribute - value relationships. |
| RDFS |
Resource Description Framework Schema |
Primitives to model basic ontologies with RDF. |
| OIL |
Ontology Interchange Language |
Primitives to model ontologies from frame - based languages,
formal semantics and reasoning support based on descriptive logic,
a proposal for syntatic interchange of annotations.
It is compatible with RDF Schema |
| DAML |
DARPA Agent Markup Language |
It is formed by DAML-ONT, (a language of ontologies) and
DAML - Logic (a language able to express axioms and rules),
it is less compatible with RDF than OIL. |
| OWL |
Web Ontology Language |
W3C Recommandation
2004-02-10; 2009-10-27; 20010-06-22; |
| XOL |
Ontology Exchange Language |
Simplicity, a generic approach to define ontologies.
It has two syntactical variants based on XML and RDF Schema. |




















